Chap 2 序列构成的数组
2.1 内置序列类型
- 容器序列 存放的是所包含的任意类型的对象的引用。list, tuple, collections.deque等
- 扁平序列 存放的是值,是一段连续的内存空间,更为紧凑,但只能存放字符、字节和数值这种基础类型。str, bytes, bytearray, memoryview, array.array等
或者根据能否被修改来分类:
- 可变序列 list, bytearray, array.array, collections.deque和memoryview。
- 不可变序列 tuple, str, bytes
2.2 列表推导和生成器表达式
列表推导 list comprehension
1
codes = [ord(symbol) for symbol in symbols]
通常的原则是,只用列表推导来生成新的列表。
Python 3之后列表推导不出现变量泄露。
- 注:Python会忽略代码里[]、{}和()中的换行。
列表推导与笛卡儿积
用列表推导可以生成两个或两个以上的可迭代类型的笛卡儿积,笛卡儿积是一个列表,列表中的元素为输入的可迭代元素构成的元组。1
2
3
4
5
6colors = ['black', 'white']
sizes = ['S', 'M', 'L']
# 先以color排序
tshirts = [(color, size) for color in colors for size in sizes]
# 先以size排序
tshirts = [(color, size) for size in sizes for color in colors]
生成器表达式
生成器表达式可以逐个产出元素,而不是先建立一个完整的列表。语法跟列表推导差不多,将[]换乘()。1
2
3
4colors = ['black', 'white']
sizes = ['S', 'M', 'L']
for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes):
print(tshirt)
与列表推导不同,使用生成器表达式后,内存里不会留下一个有6个组合的列表,因为生成器表达式会在每次for循环运行时才生成一个组合。
2.3 元组
元素是对数据的记录,它的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。 元组不仅仅是不可变的列表
元组拆包
平行赋值1
2coordinates = (22, -118)
latitude, longitude = coordinates
用*运算符把一个可迭代对象拆开作为函数的参数:1
2t = (20, 8)
quotient, remainder = divmod(*t)
如果只对元组中部分数据感兴趣,可以使用_占位符。
还可以使用*来处理剩下的元素, 以*args来获取不确定数量的参数1
2
3
4
5a, b, *rest = range(5)
print(a, b, rest)
#(0, 1, [2, 3, 4])
head, a, b = range(5)
#([0, 1, 2], 3, 4)
具名元组
collections.namedtuple可以用来构建一个带字段名的元组和一个有名字的类。1
2
3
4
5
6from collections import namedtuple
City = namedtuple('City', 'name country population coordinates')
# 具名元组的创建需要两个参数,一个是类名,另一个是类名各个字段的名称
tokyo = City('Tokyo', 'JP', 36.933, (35, 139))
# 以一串参数的形式将数据传入构造函数里,而元组的构造函数tuple()只能接受单一的可迭代对象
# tokyo.population 可以直接访问字段信息
具名元组的常用属性有:
- _fields 包含这个类所有字段的元组
- 类方法 _make(iterable) 接受一个可迭代对象来生成这个类的实例,作用和 City(*data_tuple) 相同
- 实例方法 _asdict() 将具名元组以collections.OrderedDict的形式返回
2.4 切片
切片和区间都会忽略最后一个元素
对对象进行切片
s[a:b:c]表示在a和b之间以c为间隔取值。c为负值表示反向取值。这种用法只能作为索引或者下标在[]之间返回一个切片对象。
Python会调用s.__getitem__(slice(start, stop, step)).
多维切片和省略
[]运算符还可以是用以逗号分开的多个索引或者切片。比如numpy中numpy.ndarray就可以用a[i,j]或者a[m:n, i:j]的方式来获取。对象的特殊方法__getitem__和__setitem__需要以元组的形式来接收a[i, j]中的索引.
省略是三个英文句号...。如果x是四维数组,x[i, ...]就是x[i, :, :, :]
给切片赋值
如果把切片放在赋值语句的左边,或者将他作为del操作的对象,可以对序列进行嫁接、切除或者就地修改。
2.5 对序列进行+和*
+号两侧的序列由相同类型的数据所构成,不会对原序列进行修改, 而是新建一个类来作为拼接的结果。*号将序列复制几份然后拼接起来,同样不就地修改。1
2my_list = [['_']] * 3
# 包含的3个元素是对同一个列表的引用
应该为:1
board = [['_'] * 3 for i in range(3)] # correct
2.6 序列的增量赋值
+=和*=的表现取决于他们第一个操作对象。+=的特殊方法是__iadd__,但是如果一个类没有实现这个方法的话,会退一步调用__add__, 先计算a+b, 得到一个新的对象, 然后赋值给a。
所以对于不可变序列进行重复拼接操作效率会很低。
2.7 list.sort方法和内置函数sorted
list.sort会就地排序,这方法的返回值是None。(如果一个函数或者方法对对象进行的是就地改动,那么返回值就为None)
而sorted会返回一个新建的列表,它可以接收任何形式的可迭代对象,包括不可变序列和生成器。list.sort和 sorted都有两个参数:
- reverse 如果为true,为降序输出。默认值为false
- key 会作用在每个元素上,所产生的结果是算法依赖的对比关键字。比如key=str.lower会实现忽略大小写的排序, key=len会进行字符串长度的排序。
2.8 用bisect来管理已排序的序列。
bisect模块包含bisect和insort两个主要函数,都是利用二分查找算法来在有序序列中查找或插入元素。用bisect来搜索
bisect(haystack, needle)表示在 haystack 里搜索 needle 的位置,该位置满足的条件是:把 needle 插入后还能保持升序。
可以先用bisect(haystack, needle)查找index,然后用haystack.insert(index, neddle)来插入新值。 但是insort比这个方法更快。用bisect.insort插入新元素
insort(seq, item)将 item 插入 seq 中,并且保持 seq 的升序。
2.9 数组
如果要存放的是1000万个浮点数时,array 的效率比列表高得多,因为它背后存的并不是 float 对象,而是数字的机器翻译。
Python 创建数组需要类型码,用于表示在底层的 C 语言应该存放怎样的数据类型。1
2
3from array import array
from random import random
floats = array('d', (random() for i in range(10**7)))
内存视图
memoryview 是一个内置类,让用户在不复制内容的情况下操作一个数组的不同切片。
双向队列和其他形式的队列
利用append和pop方法,可以将列表当成栈或队列来使用,但是删除列表元素是比较麻烦的操作。collections.deque是一个线程安全、可以快速从两端添加或者删除元素的数据类型。
- s.append(e) 添加一个元素到最右侧
- s.appendleft(e) 添加一个元素到最左侧
- s.extend(i) 将可迭代对象i中的元素依次添加到尾部
- s.extendleft(i) 将可迭代对象i中的元素依次添加到头部
Chap 3 字典和集合
3.1 泛映射类型
标准库里的所有映射类型都是利用dict来实现的, 因此只有可散列的数据类型才能用作这些映射里的键,(值无要求)。
可散列的数据类型
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现__hash__()方法,和__eq__()方法来跟其他键作比较,如果这两个可散列对象是相等的,那么它们的散列值一定相等。
原子不可变数据类型(str, bytes 和数值类型)都是可散列类型。
3.2 字典推导
Python2.7 后将列表推导和生成器表达式的概念移植到了字典上。1
2
3
4
5
6DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States')
]
country_code = { country: code for code, country in DIAL_CODES}
3.3 常见的映射方法
page 57
用setdefault处理找不到的键
1 | my_dict.setdefault(word, []).append(location) |
等同于1
2
3if key not in my_dict:
my_dict[key] = []
my_dict[key].append(location)
后者需要至少两次的键查询,如果键不存在,需要3次。
而setdefault只需要一次。
3.4 映射的弹性键查询
setdefault是在插入值的时候检查键, 如果我们在单纯查找键的之后,也能在键不存在的时候得到一个默认值,有两种方法:
- 通过defaultdict这个类型,而不是普通的dict类
- 定义一个dict的子类,在子类中实现
__missing__方法
defaultdict
用户在创建defaultdict对象的时候,需要给构造方法提供一个可调用对象,在__getitem__找不到键的时候调用它,返回某个默认值。
- 创建
dd = defaultdict(list),访问键new-key不存在 - 调用
list()生成一个新的列表 - 将这个列表作为值,
new-key作为键,放在dd中 - 返回这个列表的引用
如果在创建defaultdict的时候没有指定default_factory,查询不存在的键会报错。default_factory只对__getitem__有效
特殊方法missing
所有映射类型在处理找不到的键时都会牵扯到__missing__方法。__missing__方法只对__getitem__有效,对get或contains无效。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class StrKeyDict0(dict): # <1>
def __missing__(self, key):
if isinstance(key, str): # <2>
raise KeyError(key)
return self[str(key)] # <3>
def get(self, key, default=None):
try:
return self[key] # <4>
except KeyError:
return default # <5>
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys() # <6>
1 | Tests for item retrieval using `d[key]` notation:: |
3.5 字典的变种
在collections模块中,除了defaultdict之外,还有:
- collections.OrderDict: 添加键的时候会保持顺序。
- collections.ChainMap: 可以容纳数个不同的映射对象,在进行键查找的时候,这些对象会被当作一个整体被逐个查找,直到这个键被找到为止。
- collections.Counter: 给键提供整数计数器
- collections.UserDict: 把标准dict用纯Python实现
3.6 子类化UserDict
倾向于用UserDict而不是从dict继承,主要是因为后者会在某些方法的实现上走捷径,使得我们需要在子类中重写。
UserDict不是dict的子类,在UserDict中的data属性是dict的实例,是UserDict最终存储数据的地方。
3.7 不可变映射类型
标准库里的所有映射类型都是不可变的。
从Python3.3,types模块中引入了一个封装类名叫MappingProxyType, 如果给这个类一个映射,他会返回一个只读的映射视图。1
2
3from types import MappingProxyType
d = {1 : 'A'}
d_proxy = MappingProxyType(d)
d中的内容可通过d_proxy查看,并且是随着d动态更新的。但是不能对d_proxy进行修改。
3.8 集合论
集合的本质是许多唯一对象的聚集。-> 可以用于去重。
集合中的元素必须是可散列的,但set本身是不可散列的,而frozenset可以。
中缀运算符
- a | b 返回合集
- a & b 返回交集
- a - b 返回差集
集合字面量
空集必须写成set()的形式,否则{}会被认为是字典。而非空集,可以以数学形式写出,即{1,2,3,4}.
遇到{1,2,3}这样的字面量,Python会利用BUILD_SET字节码来创建集合。
而构造方法set([1,2,3])会先用set来查询构造方法,然后新建一个列表,再把这个列表传入构造方法中。
而frozenset没有对应的特殊字面量句法,只能使用构造方法frozenset([1,2,3])
集合推导
1 | from unicodedata import name |
集合的操作
3.9 dict和set的背后
字典中的散列表
散列表是一个稀疏数组,散列表中的单元一般称为表元,表元大小一致。
在dict的散列表中,每个键值对占用一个表元,每个表元有两个部分,一个是对键的引用,一个是对值的引用。可以通过偏移量来读取某个表元。
Python会设法保证大概还有三分之一的表元为空,所以在即将到达这个阈值时,原散列表会被复制到更大的空间里。
要把对象放入散列表,首先计算这个元素键的散列值,Python中用hash()。
- 散列值和相等性
内置的hash()可以用于所有内置类型对象。自定义对象调用hash()运行的是自定义的__hash__。
如果两个对象在比较时是相等的,它们的散列值也必须相等。
在Python3.3之后,str, bytes和datetime对象的散列值计算时多了随机加盐的过程,所加盐值是Python进程内的一个常量,每次启动Python解释器会生成不同的盐值。这是为了防止DOS攻击。 - 散列表算法
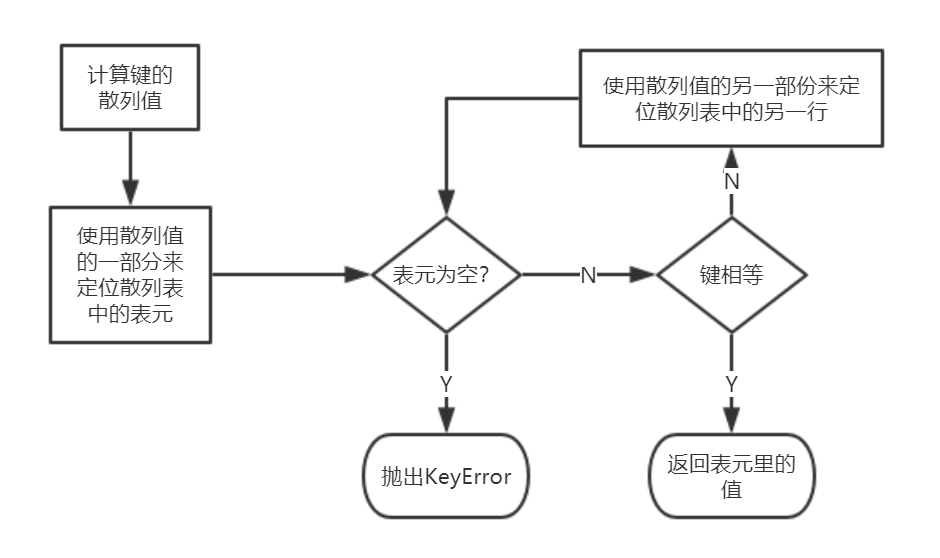
dict的实现及其导致的结果
- 键必须是可散列的
- 字典在内存上的开销巨大
- 键查询很快
- 键的次序取决于添加顺序
- 往字典里新加键可能会改变已有顺序
加键时可能会导致字典被扩容。所以不要对字典同时进行迭代和修改操作
set的实现以及导致的结果
set和frozenset在散列表中存放的只有元素的引用。
- 元素必须是可散列的
- 很消耗内存
- 可以高效判断元素是否存在于集合内
- 元素的次序取决于添加顺序