包括对象(第8、9章)、序列(第10章)、接口(第11章)、继承(第12章)、重载运算符(第13章)和生成器(第14章)
Chap 8 对象引用、可变性和垃圾回收
8.1 变量不是盒子
对于引用式变量来说,说把变量分配给对象更合理,毕竟,对象在赋值前就创建了。
为了理解Python中赋值语句,应该始终先读右边。对象在右边创建或获取,之后左边的变量才会绑定到对象上。
8.2 标识、相等性和别名
变量不过是标注,所以对象可以被贴上多个标注,这些多个标注就是别名。
1 | a = {'name': 'Charles'} |
==比较值,而is比较标识。通常我们关注值,所以==的使用比较多。但是在变量和单例值之间比较时,应该使用is:1
2x is None
x is not None
is速度比较快,因为不能重载。而a==b等同于a.__eq__(b).
每个变量都有标识、类型和值。对象一旦创建,它的标识就不会变;可以把标识看作对象在内存中的地址。
is运算符比较两个对象的标识;id()函数返回对对象标识的整数表示。
元组的相对不可变性
元组保存的是对象的引用,如果引用的元素可变,即使元组本身不可变,元素依然可变。
元组的不可变性其实是指tuple数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
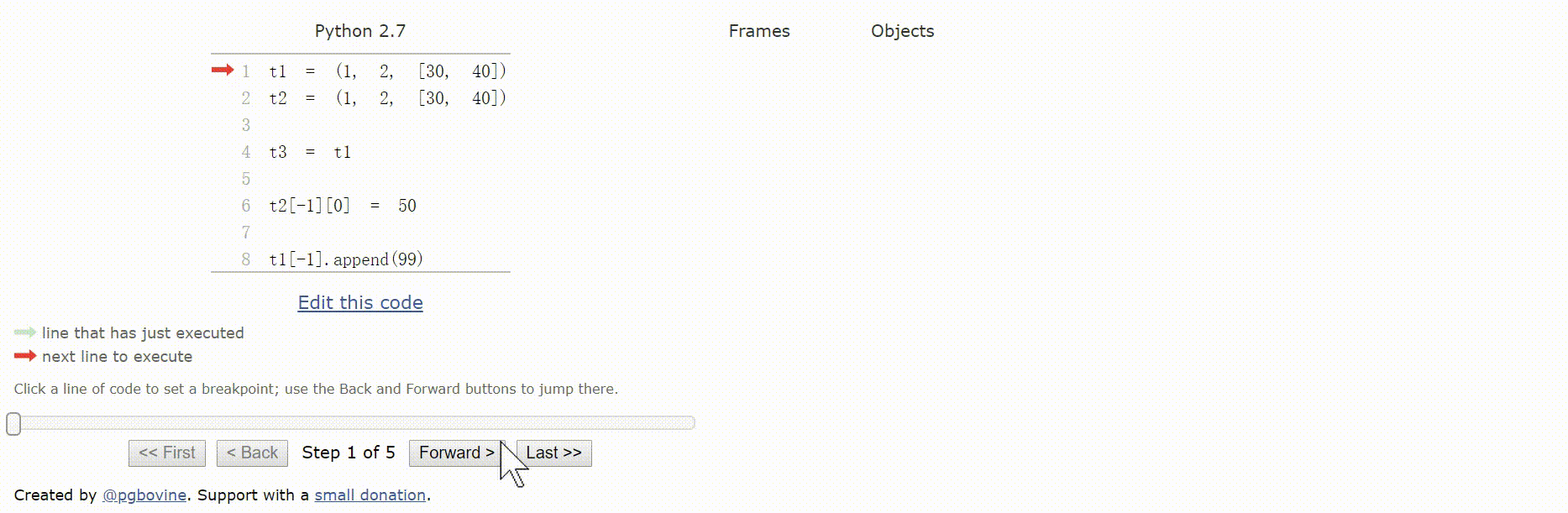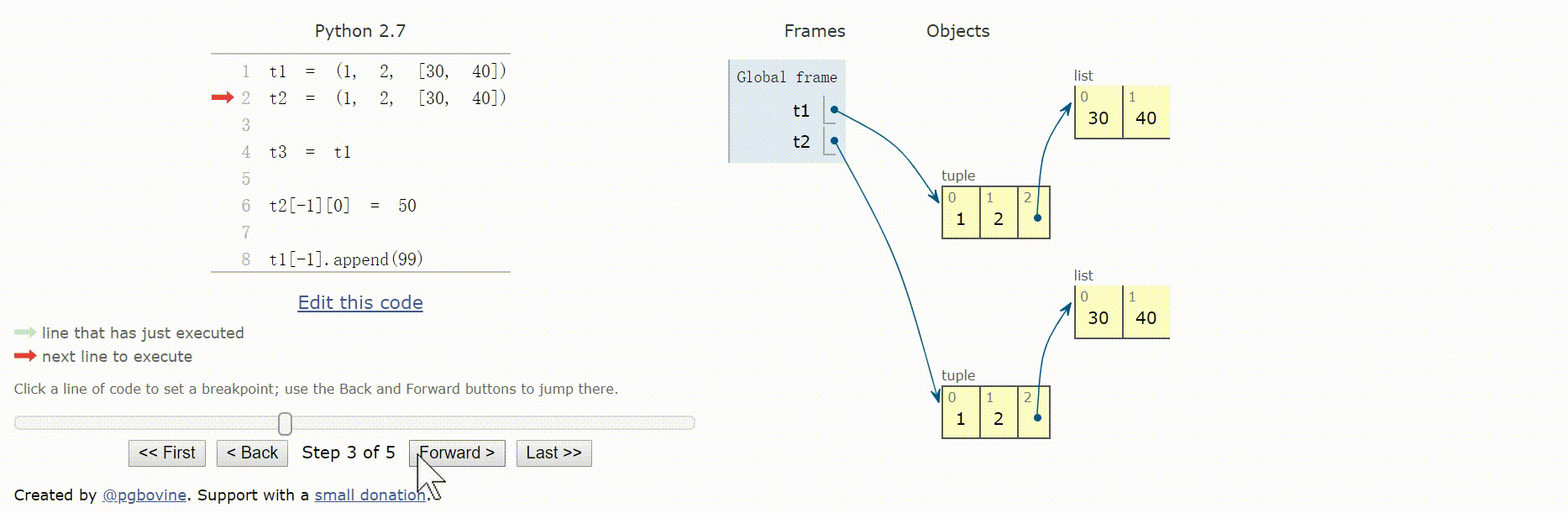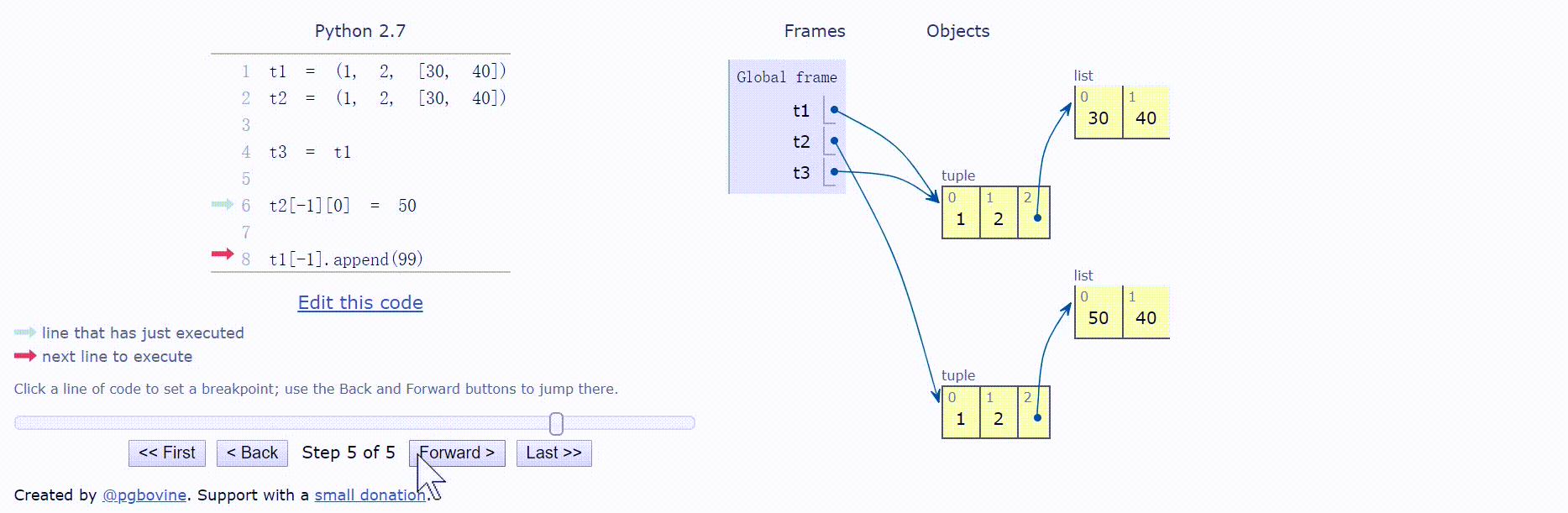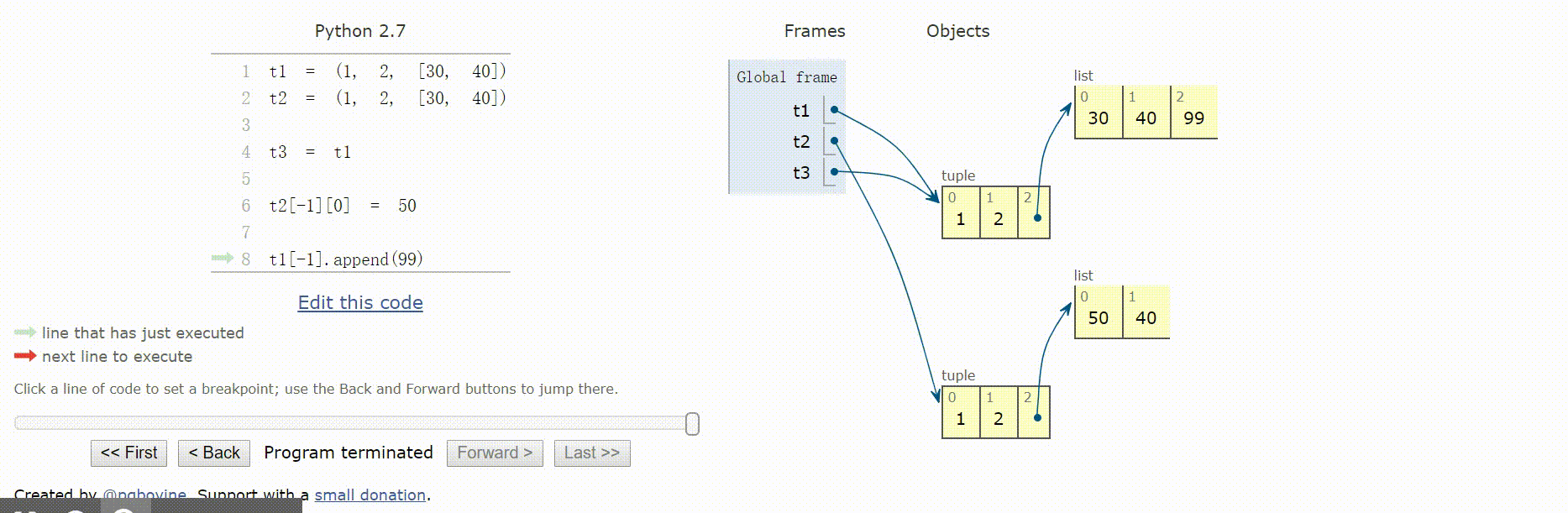
8.3 默认做浅复制
复制列表(或多数内置的可变集合)最简单的方法是使用内置的类型构造方法:l2 = list(l1)
或者使用简洁的l2 = l1[:]语句。
上述两种方法做的都是浅复制,即复制了最外层容器,副本中的元素是源容器中元素的引用。
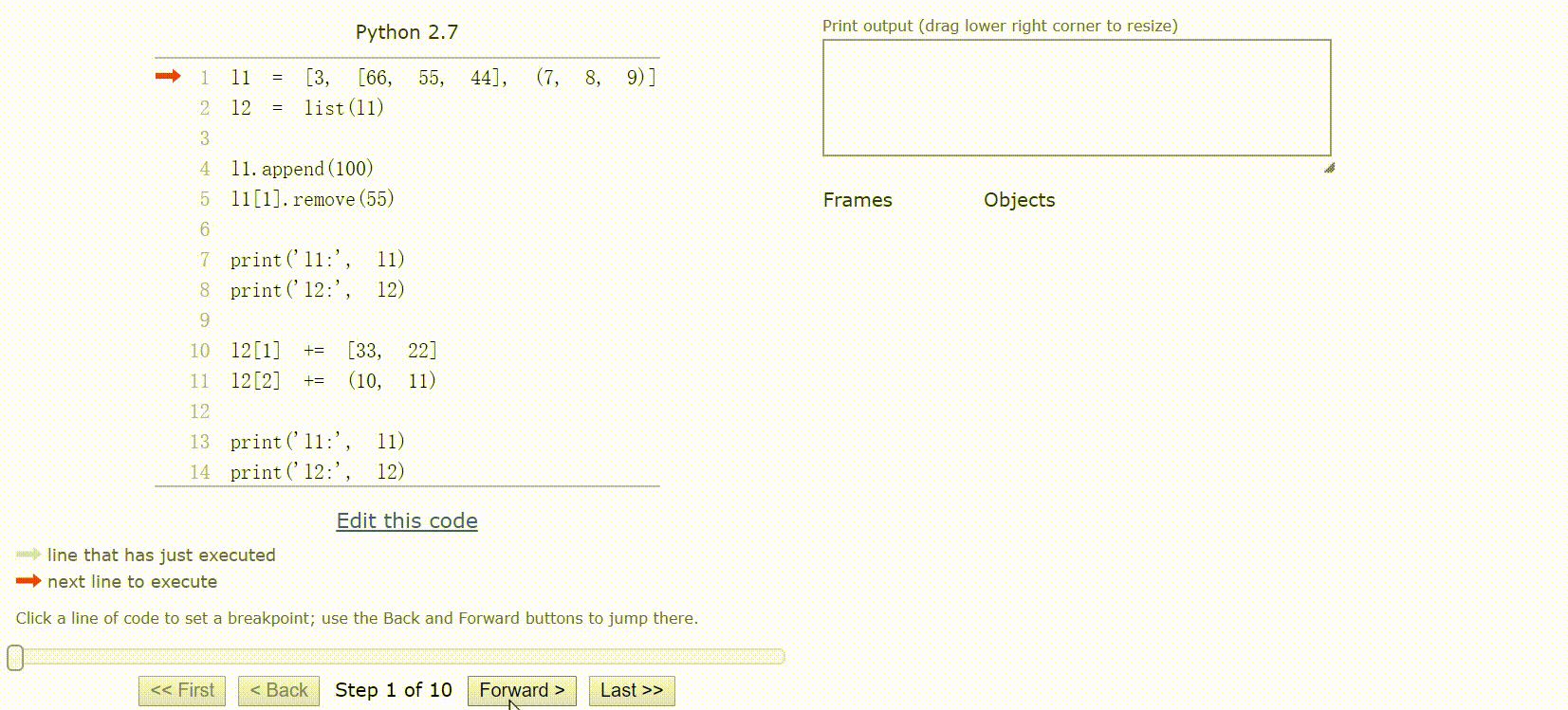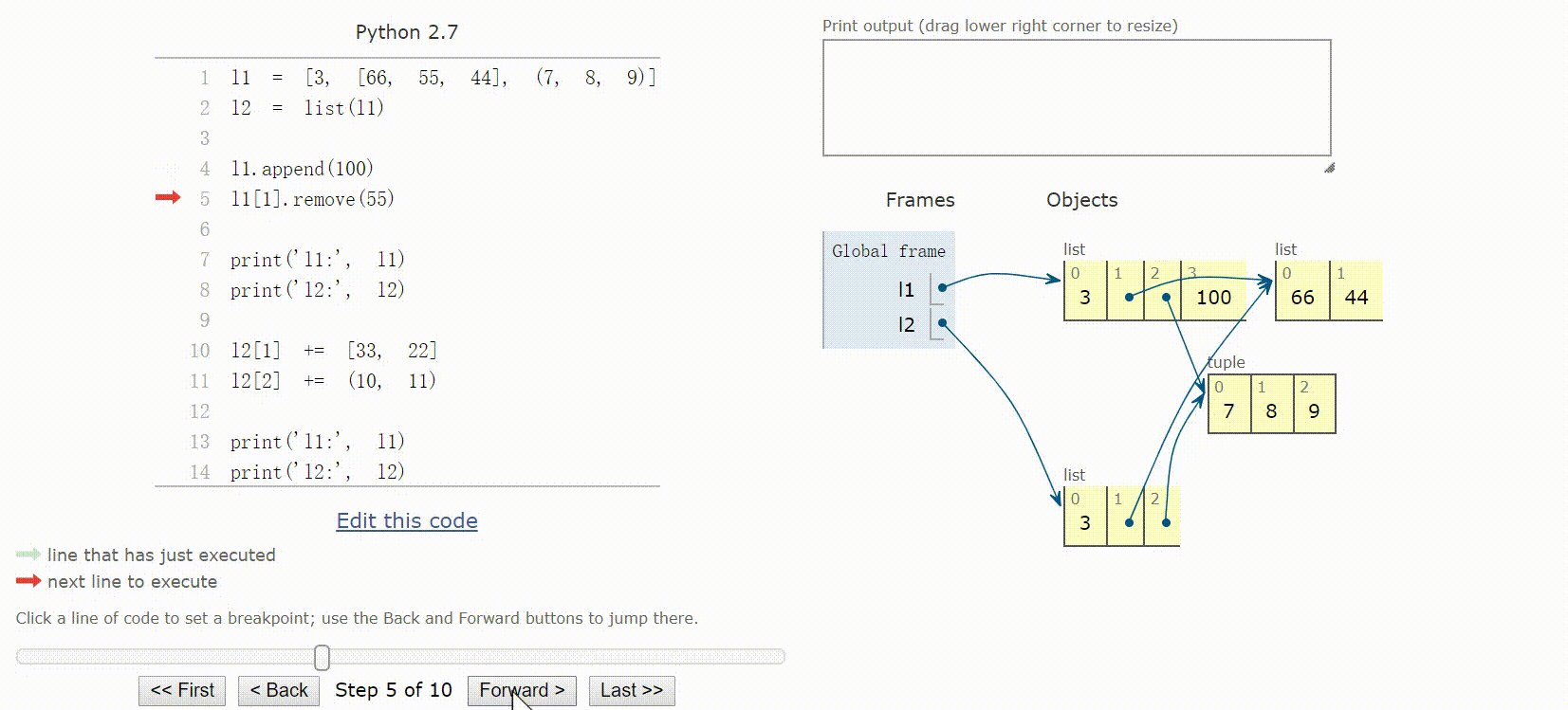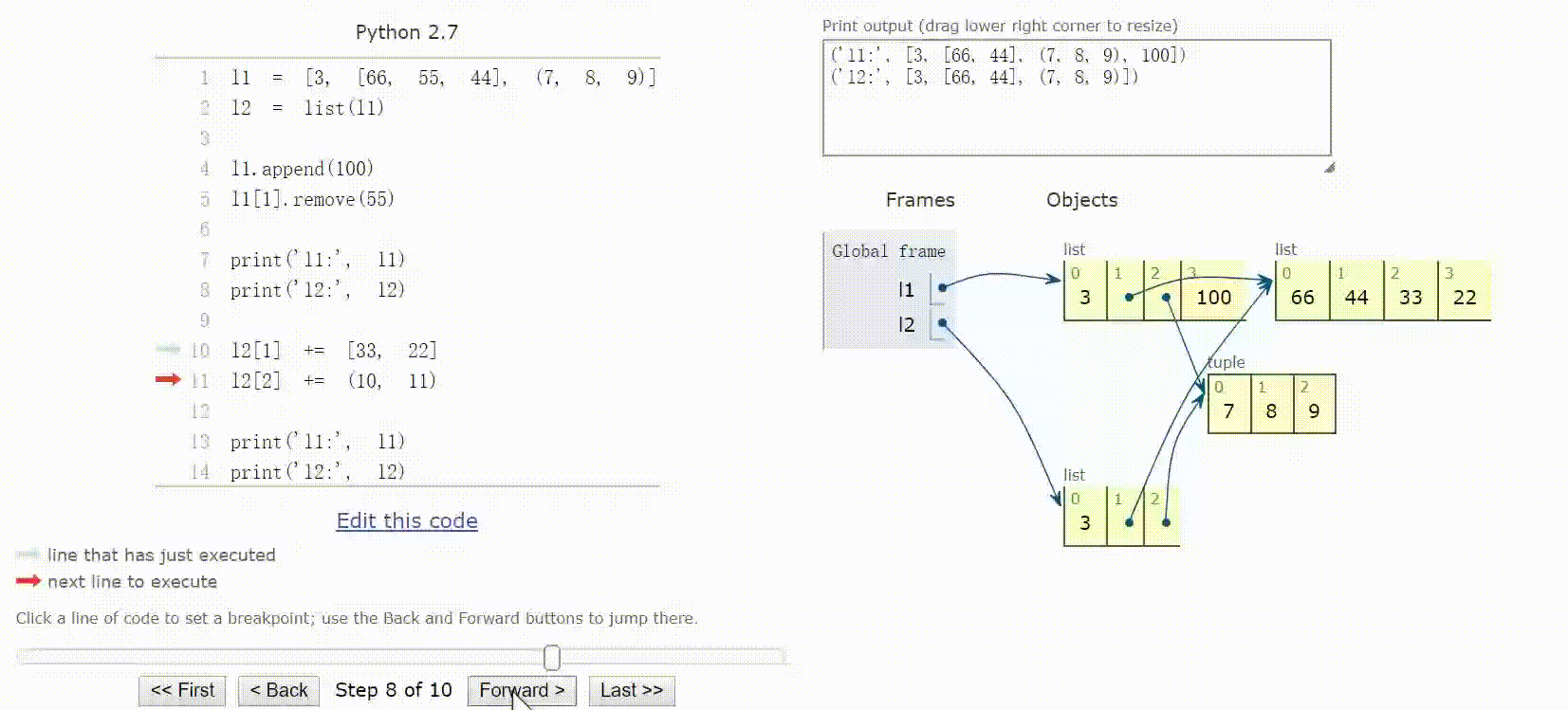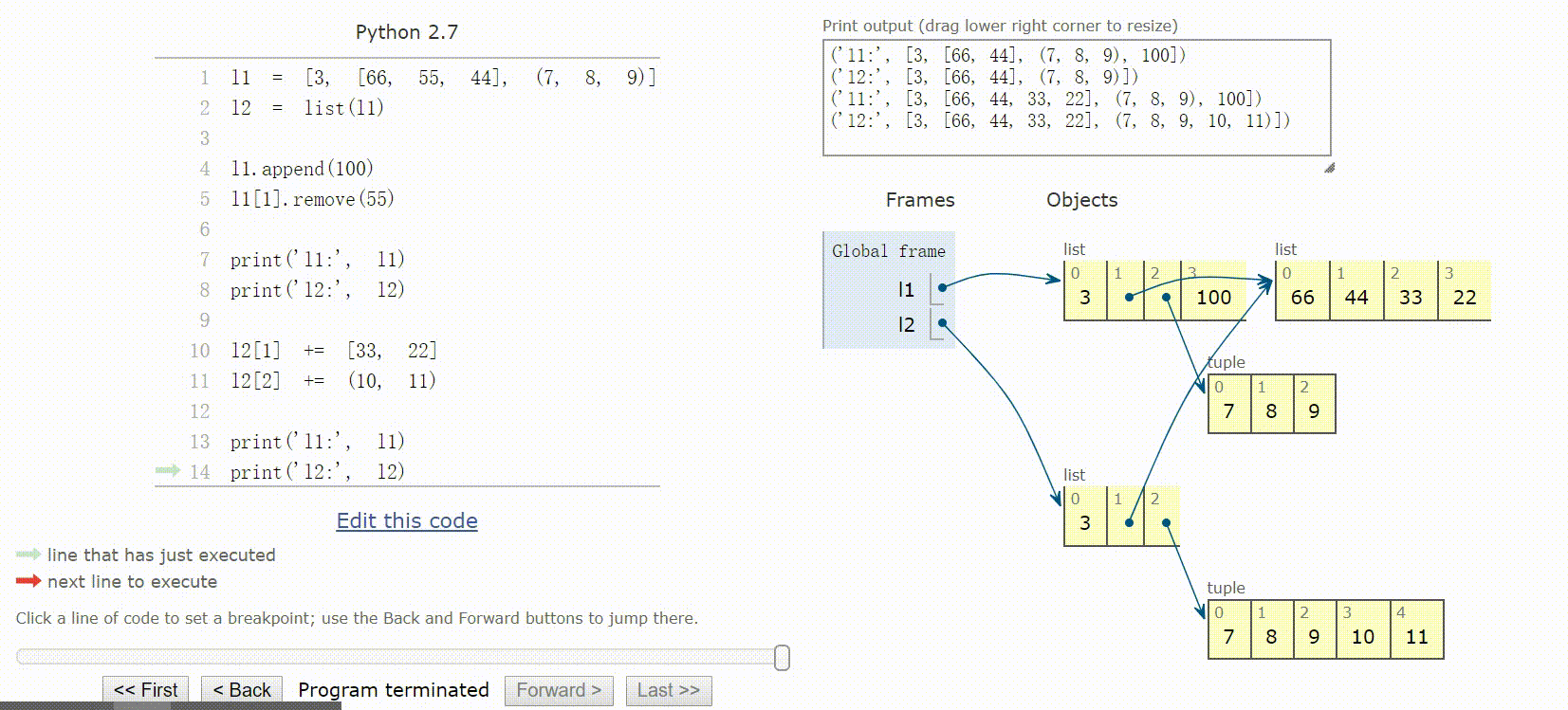
对于元组来说,+=创建一个新元组,重新绑定给变量。而对于列表来说,+=是个就地操作,对象不变。
深复制 && 浅复制
copy模块提供的deepcopy和copy能为任意对象做深复制和浅复制。1
2
3
4import copy
a = {'name': 'english'}
b = copy.copy(a) # 浅复制
c = copy.deepcopy(a) # 深复制
8.4 函数的参数作为引用时
Python唯一支持的参数传递模式是共享传参(call by sharing),指函数的各个形式参数获得实参中的各个引用的副本,也就是说,函数内部的形参是实参的别名。
所以函数可能会修改作为参数传入的可变对象。 –> 避免使用可变对象做参数默认值。
通常使用None作为接受可变对象的参数的默认值,在类中直接把参数赋值给变量时要注意,是真的需要修改参数,还是可以通过创建副本来避免麻烦。
8.5 del和垃圾回收
对象绝不会自行销毁;然而,无法得到对象时,可能会被当作垃圾回收。
del语句删除名称,而不是对象。del命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
CPython中使用引用计数来决定是否垃圾回收。当引用计数归零,对象就被销毁。
8.6 弱引用
弱引用不会增加对象的引用数量,即不会妨碍所指对象(引用的对象目标)被当作垃圾回收。
弱引用在缓存应用中很有用,可以不用因为被缓存引用而始终保存缓存对象。
weakfer模块中的ref(底层接口,供高级用途)、WeakValueDictionary、WeakKeyDictionary、WeakSet是常用集合
8.7 Python对不可变类型施加的把戏
对元组t来说,t[:]不创建副本,而是返回同一个对象的引用,tuple(t)也是如此。str,bytes和frozenset实例也有这种行为。frozenset实例不是序列,不能使用[:],但是frozenset.copy()具有同样的效果。
共享字符串字面量称为驻留,Cpython还会在小的整数上使用这个策略,防止重复创建,如0、-1、42. 所以比较字符串和整数是否相等时应使用==。
8.8 小结
- 简单的赋值不创建副本
+=和*=的具体含义视左边的变量而变,如果不可变对象会创建新对象- 对现有的变量赋新值,不会修改之前绑定的变量,这叫做重新绑定。如果变量是之前对象的最后一个引用,对象会被回收
- 函数的参数以别名的形式传递。所以函数可能会修改传入的可变对象。
- 使用可变对象作为函数的参数默认值有危险,如果就地修改了参数,默认值就改变了,会影响以后默认值的使用。
Chap 9 符合Python风格的对象
9.1 对象表示形式
- repr() –> __repr__
以便于开发者理解的方式返回对象的字符串表示形式 - str() –> __str__
以便于用户理解的方式返回对象的字符串表示形式
此外还有两个特殊方法:
- __bytes__: bytes()函数调用它获取对象的字节序列表示形式
- __format__: 被内置的format()函数和str.format()方法调用,使用特殊的格式代码显示对象的字符串表示形式
9.4 classmethod 与 staticmethod
classmethod定义操作类,而不是操作实例方法。类方法的第一个参数是类本身,而不是实例。按照约定,类方法的第一个参数名为cls。
self表示一个具体的实例本身
cls表示类本身
staticmethod和classmethod非常的相似,但是不强制要求传递参数。它的本质是普通函数,但它不关注对象和对象内部属性。
1 | # https://stackoverflow.com/questions/12179271/meaning-of-classmethod-and-staticmethod-for-beginner |
9.5 格式化显示
内置的format()函数和str.format()方法把哥哥类型的格式化方式委托给相应的.__format__(format_spec)方法。format_spec是格式说明符,用于:
format(my_obj, format_spec)的第二个参数str.format()方法的格式字符串,{}里代换字段中冒号后面的部分。1
2brl = 1/2.43
'1 BRL = {rate:0.2f} USD'.format(rate=brl)
冒号左边在代换字段句法中是字段名,后面是格式说明符。
格式规范微语言是可扩展的。
如果类没有定义__format__方法,从object继承的方法会返回str(my_object)。
9.6 可散列化
使用两个前导下划线(尾部没有或只有一个下划线)把属性标记为私有的。
想要创建可散列的类型,不一定要实现特性和保护实例属性,只需正确的实现__hash__和__eq__即可。但是实例的散列值绝不应该改变。
9.7 Python的私有属性和“受保护的”属性
通过__variable的形式(尾部最多有一个下划线)命名属性,Python会把属性名存入实例的__dict__属性中,而且会在前面加上一个下划线和类名,如_myClass__variable。这个特性叫名称改写(name mangling)。 这是一种安全措施,它的目的是避免意外访问,不能防止故意修改。inst1._myClass__variable = 7这种语句能修改实例的私有属性。
也有程序员们不喜欢这种写法,他们约定使用一个下划线前缀编写受保护的属性,如self._x。
Python解释器不会对单个下划线的属性名做特殊处理,但是程序员们约定不会在类外部访问这种属性。
不过如果是模块的话,顶层名称使用一个下划线会有影响:from mymod import *不会用如前缀为下划线的名称,不过可以通过from mymod import _mymod的方式导入。
9.8 使用__slots__类属性节省空间
Python在默认情况下将实例属性存储在各个实例中名为__dict__的字典里。
字典会消耗大量内存。
通过__slots__类属性,节省大量内存。
定义__slots__的方法是:创建一个类属性,使用__slots__这个名字,并把它的值设为一个字符串构成的可迭代对象,其中的元素便是各个实例属性。1
2
3class myClass:
__slots__ = ('__x', '__y')
# more codes ...
__slots__属性告诉解释器:这个类中的所有实例属性都在这儿。 这样解释器就会在各个实例中使用类似元组的结构存储实例变量,避免使用__dict__属性。
在类中定义了__slots__之后,实例中不能有没出现在__slots__中的其他属性。
如果在__slots__中添加__dict__,实例会在元组中保存各个实例的属性,还支持动态添加属性,存储在__dict__中。
用户定义的类中默认就有__weakref__属性,如果在类中定义__slots__属性,则要手动添加__weakref__,来让对象支持弱引用。
实例特别多时才推荐使用。
每个子类都要定义__slots__属性,因为继承器会忽略继承的__slots__属性。
9.9 覆盖类属性
Python有个独特的特性:类属性可用于为实例属性提供默认值。
如果为不存在的实例属性赋值,会新建实例属性。
类属性是公开的,会被子类继承,因此可以创建一个子类,只用于定制类的数据属性,这样更具Python风格。
Chap 10 序列的修改、散列和切片
10.3 协议和鸭子类型
在Python中创建功能完善的序列类型无需使用继承,只需实现符合序列协议的方法。
在面向对象编程中,协议是非正式的接口,只在文档中定义,在代码中不定义。例如,Python中的序列协议只需要__len__和__getitem__两个方法。任何类只要使用标准的签名和语义实现了这两个方法,就能用在任何期待序列的地方。
协议是非正式的,没有强制力,因此如果你知道类的具体使用场景,通常只需要实现一个协议的部分。
10.4 切片
slice中有个indices属性,help(slice.indices)给出的信息:
S.indices(len) -> (start, stop, stride)
给定长度为len的序列,计算S表示的扩展切片的起始和结尾索引,以及步幅。超过边界的索引会被截掉。
indices将start,end和stride都变成非负数。,而且都落在指定长度序列的边界内。
10.5 动态存取属性
属性查找失败后,解释器调用__getattr__方法,简单来说,对于my_obj.x表达式,Python会检查my_obj实例有没有名为x的属性;如果没有,到类(my_obj.__class__)中查找;如果还没有,顺着继承树继续查找;如果依旧找不到,就调用my_obj所属类中定义的__getattr__方法,传入self和属性名称的字符串形式。
10.6 散列和快速等值测试
实现hash方法
functools.reduce()可以替换为sum(),关键思想是:把一系列值归约成单个值。
归约函数(reduce, map, any, all)把序列或有限的可迭代对象变成一个聚合结果
1 | import functools, operator |
reduce函数有个参数,reduce(function, iterable, initializer),如果序列为空,initializer是返回的结果,否则在归约中使用它作为第一个参数,因此应该使用恒等值。对于+, |, ^来说,应该是0, 对于*, &是1。
映射归约:把函数应用到各个元素上,生成一个新的序列(映射,map),然后计算聚合值(归约,reduce)
1 | def __hash__(self): |
实现eq方法
1 | def __eq__(self, other): |
这个方法复制两个操作数,构建两个元组进行比较,使用tuple类型的__eq__方法。1
2
3
4
5
6
7def __eq__(self, other):
if len(self) != len(other):
return False
for a, b in zip(self, other):
if a != b:
return False
return True
zip函数生成一个由元组构成的生成器。必须先比较长度,因为zip一旦有一个输入耗尽,就会立即停止生成值,而且不会抛出异常。1
2def __eq__(self, other):
return len(self) == len(other) and all(a == b for a,b in zip(self, other))
Chap 11 接口: 从协议到抽象基类
本章讨论从鸭子类型的代表特征动态协议到使接口更明确、能验证实现是否符合规定的抽象基类。
11.1 Python文化中的接口和协议
Python语言中没有interface关键字,而且除了抽象基类,每个类都有接口:类实现或继承的公开属性(方法或数据属性),包括特殊方法,如__getitem__.
按照定义,受保护的属性和私有属性不在接口中:即便只是采用命名约定实现“保护”;私有属性可以轻松地访问。
关于接口,有个实用的补充定义:对象公开方法的子集,让对象在系统中扮演特定的角色。
接口是实现特定角色的方法集合。
协议和继承没有关系。
一个类会实现多个接口,从而让实例扮演多个角色。
协议是接口,但不是正式的,只由文档和约定定义。
一个类可能只实现部分接口。
11.2 Python喜欢序列
序列协议是Python最基础的协议之一,即使对象只实现了那个协议最基本的一部分,解释器也会负责地处理。
Python会特殊对待看起来像是序列的对象。
11.3 猴子补丁
猴子补丁:在运行时修改类或模块,而不改动源码。打补丁的代码要和打补丁的程序耦合紧密,所以需要处理隐藏和没有文档的部分。
11.4 抽象基类
By Alex Martelli
鸭子类型是指忽略对象的真正类型,转而关注对象有没有实现所需的方法、签名和语义。对Python来说,这基本上避免使用isinstance检查对象的类型。
白鹅类型是指,只要cls是抽象基类,即cls的元类是abc.ABCMeta,就可以使用isinstance(obj, cls)。
抽象基类可以在代码中使用register类方法把某个类“声明”为一个抽象基类的“虚拟”子类,被注册的类要求满足抽象基类对方法名称和签名的要求,最重要的是满足底层语义契约。
有时甚至不需要注册,抽象基类也能识别子类。
11.5 抽象子类的子类
导入时,Python不会检查子类中抽象方法的实现,在运行时实例化子类才会真正检查。
在collections.abc中,每个抽象基类的具体方法都是作为类的公开接口实现的,因此不用知道实例的内部结构。
11.7 抽象基类定义与使用
虚拟子类
注册虚拟子类的方法是在抽象基类上调用register方法,注册的类会变成抽象基类的虚拟子类,而且issubclass和isinstance等函数都能识别。但是注册的类不会从抽象基类中继承任何方法和属性(不会被检查)。
为了避免运行时错误,虚拟子类要实现所需的全部方法。
注册虚拟子类可以使用类装饰器,单更常用的是把它当作函数使用。
1 | from tombola import Tombola |
类的继承关系在一个特殊的类属性中指定——__mro__,它会列出“真实”的超类,不会显示虚拟注册的基类。
11.11 小结
不要自己定义抽象基类
不要过度使用抽象基类
Chap 12 继承的优缺点
12.1 子类化内置类型
内置类型(使用C语言编写)不会调用用户定义的类覆盖的特殊方法。1
2
3
4
5
6
7class DoppelDict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, [value] * 2)
dd = DoppelDict(one=1)
dd['two'] = 2 # dd为{'one':1, 'two':[2,2]}
dd.update(three=3) # dd为{'three': 3,'one':1, 'two':[2,2]}
# 不会使用我们覆盖的__setitem__方法
这样违背了面向对象编程的一个基本原则: 始终从实例(self)所属的类开始搜索方法,即使在超类实现的类中调用也是如此。
直接子类化内置类型容易出错,用户自己定义的类应该继承collections模块中的类,比如UserDict, UserList和UserString。
12.2 多重继承和方法解析顺序
如果同级别的超类定义了同名属性,Python如何确定选择哪一个?这种冲突称为“菱形问题”。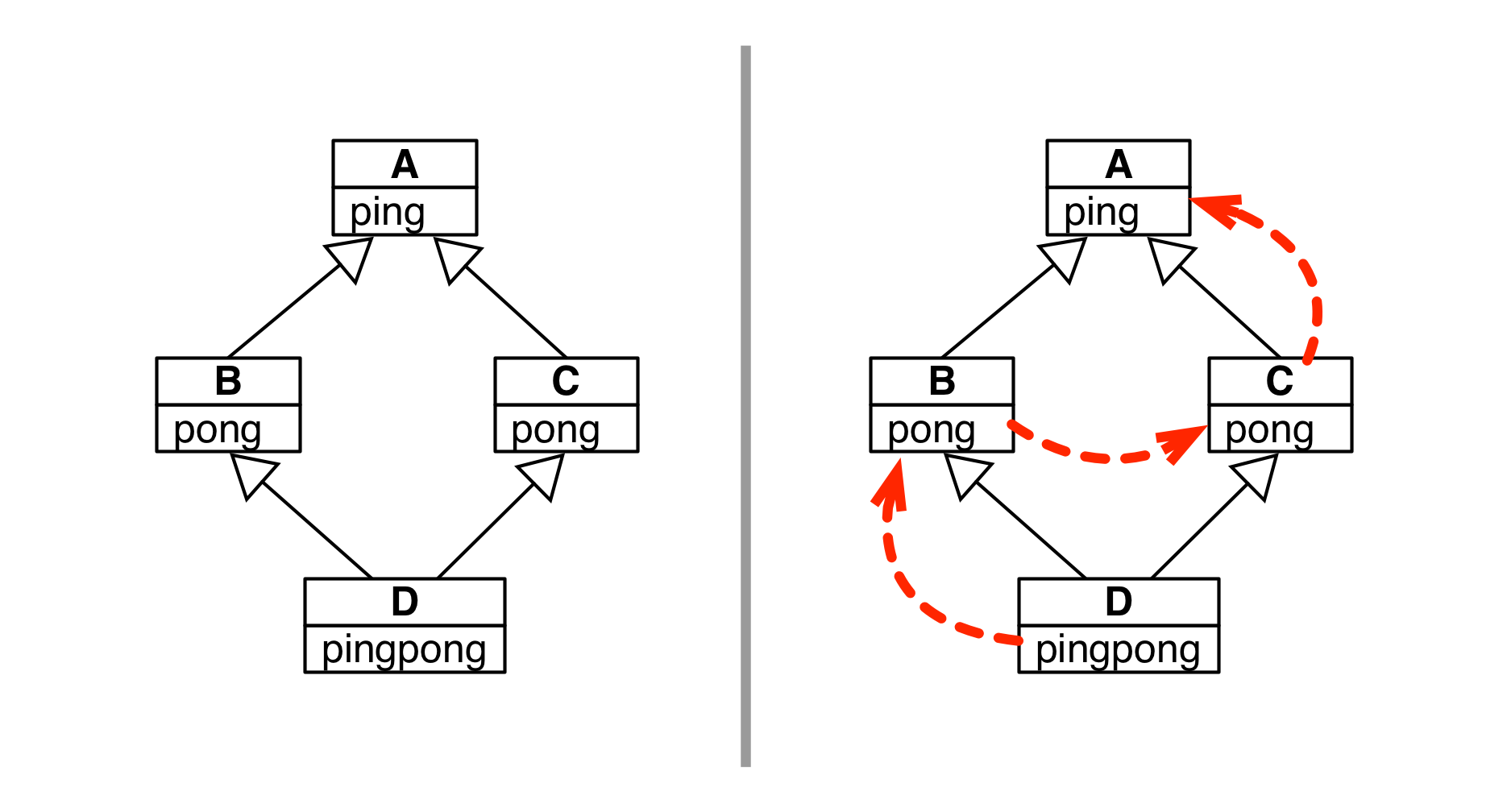
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class A:
def ping(self):
print('ping:', self)
class B(A):
def pong(self):
print('pong:', self)
class C(A):
def pong(self):
print('PONG:', self)
class D(B, C):
def ping(self):
super().ping()
print('post-ping:', self)
def pingpong(self):
self.ping()
super().ping()
self.pong()
super().pong()
C.pong(self)
B和C都实现了pong(),区别是输出的大小写不同。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 d =D()
d.ping()
ping: <__main__.D object at 0x0000019678ED55C0>
post-ping: <__main__.D object at 0x0000019678ED55C0>
d.pong()
pong: <__main__.D object at 0x0000019678ED55C0>
d.pingpong()
ping: <__main__.D object at 0x0000019678ED55C0>
post-ping: <__main__.D object at 0x0000019678ED55C0>
ping: <__main__.D object at 0x0000019678ED55C0>
pong: <__main__.D object at 0x0000019678ED55C0>
pong: <__main__.D object at 0x0000019678ED55C0>
PONG: <__main__.D object at 0x0000019678ED55C0>
直接运行d.pong()运行的是类B中的代码。在类D中的self.pong()也是B中的代码。
这是因为Python会根据方法解析顺序来遍历继承图。1
2 D.__mro__
(__main__.D, __main__.B, __main__.C, __main__.A, object)
如果想把方法调用委托给超类,推荐使用内置的super()函数。或者直接在类上调用实例方法,此时必须显式传入self参数,因为这样访问的是未绑定方法。1
2
3class D(B, C):
def ping(self):
A.ping(self)
使用super()调用方法时,会遵守方法解析顺序。1
2
3
4
5
6def pingpong(self):
self.ping() # 运行D类的ping
super().ping() # 跳过D类的ping,找到A类的ping
self.pong() # 根据__mro__,找到B类实现的pong方法
super().pong() # 同上
C.pong(self) # 忽略__mro__, 找到C类的pong
方法解析顺序不仅考虑继承图,还考虑子类声明中列出超类的顺序。如果D的声明为(C, B),那么D类的__mro__属性就会先是C。
12.4 处理多重继承
- 把接口继承和实现继承区分开
- 继承接口,创建子类型,实现“是什么”的关系
- 继承实现,通过重用避免代码重复
- 使用抽象基类显式表示接口
- 通过混入重用代码
如果一个类的作用是为多个不相关的子类提供方法实现,从而实现重用,但不体现“是什么”关系,这个类应明确定义为混入类(mixin class)。从概念上讲,混入不定义新类型,只是打包方法,便于重用。混入类绝对不能实例化,而且具体类不能只继承混入类。 - 在名称中明确指明混入
在名称中加入...MiXin - 抽象基类可以作为混入,反之不成立
- 不要子类化多个具体类
具体类可以没有,或最多只有一个具体超类。 - 为用户提供聚合类
如果抽象基类或混入的组合对客户代码非常有用,那就提供一个类,使用便于理解的方式把他们结合起来。 - 优先使用对象组合,而不是类继承
Chap 13 正确重载运算符
运算符重载的作用是让用户定义的对象使用中缀运算符或一元运算符。
13.1 运算符重载基础
- 不能重载内置类型的运算符
- 不能新建运算符,只能重载现有的
- 某些运算符不能重载 —— is, and, or, not(但是位运算符&、|、~可以)
13.2 一元运算符
- - (__neg__) 一元取负算数运算符
- (__pos__) 一元取正算数运算符,通常
x == +x。The unary + (plus) operator yields its numeric argument unchanged.
- (__pos__) 一元取正算数运算符,通常
- ~ (__invert__) 对整数按位取反,定义为
~x == -(x+1)
这些特殊方法只有一个参数self。
遵守运算符的一个规则:始终返回一个新对象,也就是不能修改self,要创建并返回合适类型的新实例。
多数时候,+最好返回self的副本。1
2
3
4
5
6
7
8def __abs__(self):
return math.sqrt(sum(x * x for x in self))
def __neg__(self):
return Vector(-x for x in self)
def __pos__(self):
return Vector(self)
13.3 重载加法运算符+
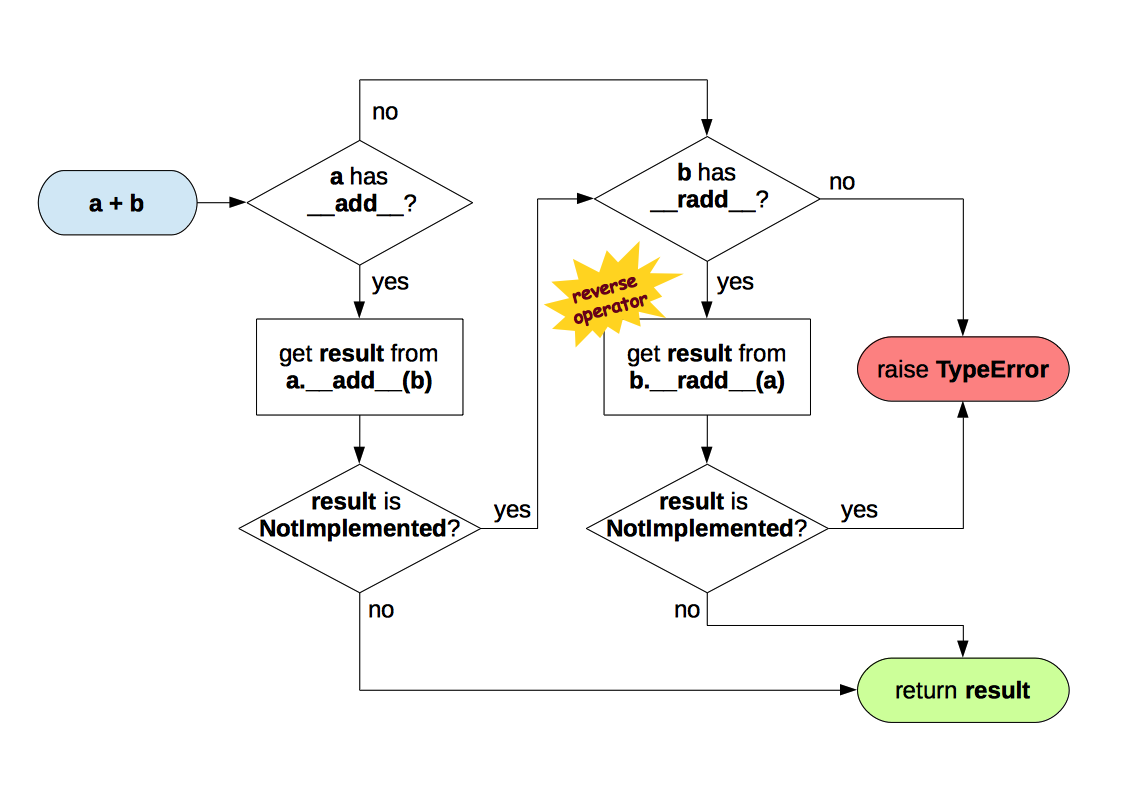
__radd__是__add__的反向版本,在右操作数上调用。
NotImplemented是特殊单例值,而NotImplementedError是一种异常,抽象类中的占位方法把它抛出,提醒子类必须覆盖。
如果由于类型不兼容而导致运算符特殊方法无法返回有效结果时,应返回NotImplemented,而不是TypeError,这样另一个操作数所属的类型还有机会执行运算,即反向运算。
1 | def __add__(self): |
13.4 重载标量乘法运算符 *
Python中的*为标量积,各个分量会乘以后面的数字,也叫元素级乘法。
对于乘法来说,需要考虑操作数类型不兼容的问题。在加法重载中,使用了鸭子类型,捕获TypeError。在这里,可以使用白鹅类型,使用isinstance()检查类型,但是不硬编码具体的类型,而检查numbers.Real抽象基类。这个抽象基类覆盖我们所需的类型,而且可以兼容后续被声明为该抽象基类的真实/虚拟子类的数值类型。
1 | def __mul__(self, scalar): |
点乘,在Numpy中使用numpy.dot()函数计算,Python3.5引入@中缀运算符来计算点积。
13.5 众多比较运算符
- 正向和反向调用使用同一系列方法。
- 对
==和!=来说,如果反向调用失败,Python会比较对象的id,而不抛出TypeError
Python3 之后对于__ne__,返回对__eq__结果的取反。
13.6 增量赋值运算符
如果一个类没有实现就地运算符,增量赋值运算只是语法糖:a+=b等同于a=a+b。如果定义了__add__,+=也能使用。
如果实现了就地运算符,就会就地修改左操作数,不会创建新的对象。但是对于不可变类型来说,这个运算符依然等同于语法糖。
与+相比,+=对第二个操作数更宽容。
13.7 小结
对于操作数类型来说,有两种处理方法:
- 鸭子类型,直接执行运算,如果有问题再抛出TypeError异常
- 白鹅类型,通过显示检查抽象基类来得到类型结果
Chap 14 可迭代的对象、迭代器和生成器
14.1 序列可迭代的原因:iter函数
解释器迭代对象x时,会调用iter(x)。内置的iter函数有以下作用:
- 检查对象是否实现
__iter__方法,如果实现了就调用,获取一个迭代器 - 如果没有实现
__iter__,但是实现了__getitem__,Python会创建一个迭代器,尝试按顺序(从索引0开始)获取元素 - 如果尝试失败,Python抛出TypeError异常。
14.2 可迭代对象与迭代器的对比
可迭代的对象
使用iter内置函数可以获取迭代器的对象。如果实现了能返回迭代器的__iter__方法,那么对象就是可迭代的。序列都可以迭代;实现了__getitem__方法,而且参数是从零开始的索引,这种对象也可以迭代。
Python从可迭代的对象中获取迭代器。
标准的迭代器接口有两个方法:
__next__
返回下一个可用元素,如果没有,抛出StopIteration__iter__
返回self,以便在应该使用可迭代对象的地方使用迭代器。
迭代器
实现了无参数的__next__方法, 返回序列中的下一个元素;如果没有就抛出StopIteration。Python中迭代器还实现了__iter__方法,因此迭代器也可以迭代。
14.4 生成器函数
1 | def __iter__(self): |
只要函数的定义体内有yield关键字,这个函数就是生成器函数。调用生成器函数会返回一个生成器对象。也就是说,生成器函数是生成器工厂。
14.5 惰性实现
惰性求值(laze evaluation)和及早求值(eager evaluation)是两个相反的方法。
re.finditer函数是re.findall的惰性版本,返回的不是一个列表,而是一个生成器,按需生成re.MatchObject实例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
for match in RE_WORD.finditer(self.text):
yield match.group()
match.group()方法从MatchObject实例中提取匹配正则表达式的具体文本。
14.6 生成器表达式
简单的生成器函数可以替换为生成器表达式。
生成器表达式可以理解为列表推到的惰性版本:不会迫切的构建列表,而是返回一个生成器,惰性按需生成元素。
1 | def __iter__(self): |
如果生成器表达式要分成多行写,倾向于定义生成器函数,以便提高可读性。此外,生成器函数有名称,可以重用。
14.9 标准库中的生成器函数
p349 - p356
itertools.dropwhilewould stop dropping when failed and take the rest.itertools.takewhilewound stop taking when failed and drop the rest.
14.12 深入分析iter函数
iter函数可以传入两个参数,第一个参数是可调用对象, 用于不断调用,产出各个值;第二个参数是哨符,当可调用对象返回这个值时,触发迭代器抛出StopIteration异常,而不产出哨符。